
一、基础知识准备
1.1 内存
万事万物在计算机中最终会归为二进制组合数字表示。
然而,对于现实世界的事物与事物关系,不能单纯使用某个数字和另一个数字来表示,就好比,使用年龄这一个维度来表示人类这个事物未免有些不妥。因为人类这个事物会包含很多的属性,比如姓名、年龄、身高、体重等属性,只有这些属性组合在一起才可以构成人类的基本特征。
然而,不同属性的设计会表现出这个事物在现实世界的表现意义,如学号、身份证、所属年级等属性的组合,很具象表示学生这个事物。
再回到第一句话,计算机只能使用数学上纯数字来标识事物,在硬件内存中表示上述复杂的事物结构呢?这就需要引入结构体的概念:
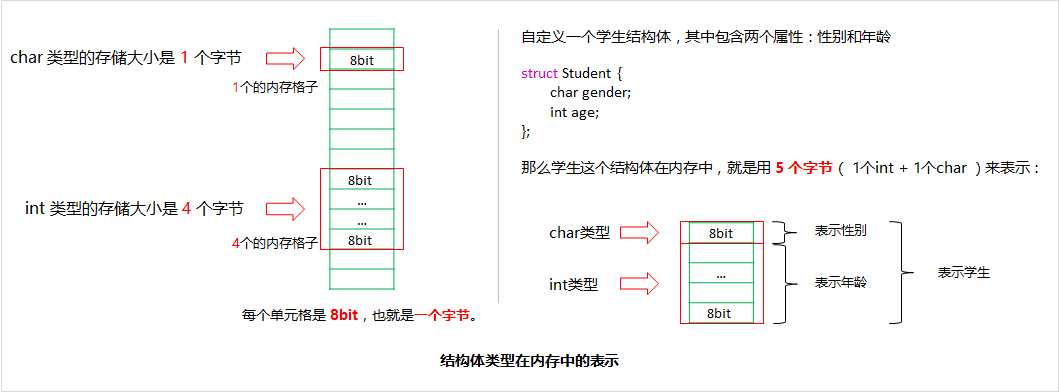
内存是一块连续的可存储空间, 一般最小的存储单位是一个字节(8bit),这里将一个字节的存储单位叫一个格子,那么内存可以表示为连续的格子组成,每一个格子可以表示的最大数值范围是 256( 2 的 8 次方),比如一个学生的学号是20190909001,那这么大的数字在一个内存格子里放不下,该怎么办呢?
答案很简单,多使用几个格子来表示不就行了对吗,因此,有一块连续的存储空间,可以任意使用,想怎么存就怎么存,那么规定每四个格子表示一个事物,那么这个四个格子可以表示的数字范围是 4G(4个2的8次方相乘),这个 4G 数字单位很眼熟(不就是32位计算机最大的内存限制嘛),这四个格子可以表示的范围(42亿多)完全可以够上述的学号属性使用了,毕竟没有哪所学校会设计学生学号长度超过亿位数。
1.2 数据类型
在 C 语言中,将这四个内存格子为一个单位的数字数据,其类型成为int,一个内存格子的数字数据类型为char,C 语言中还定义了一些现实世界常用的数字数据类型,这些类型是用来约束整数数据的:
| 类型 | 存储大小 | 值范围 |
|---|---|---|
| char | 1 字节 | -128 到 127 或 0 到 255 |
| unsigned char | 1 字节 | 0 到 255 |
| signed char | 1 字节 | -128 到 127 |
| int | 2 或 4 字节 | -32,768 到 32,767 或 -2,147,483,648 到 2,147,483,647 |
| unsigned int | 2 或 4 字节 | 0 到 65,535 或 0 到 4,294,967,295 |
| short | 2 字节 | -32,768 到 32,767 |
| unsigned short | 2 字节 | 0 到 65,535 |
| long | 4 字节 | -2,147,483,648 到 2,147,483,647 |
| unsigned long | 4 字节 | 0 到 4,294,967,295 |
注意:上表中的数据类型是针对整型数据不用的存储大小(内存格子)会对应不同的数据类型,C 语言中还定义了其他数据的数据类型:枚举类型、void 类型、派生类型。
1.3 结构体
在第 2 小节中已经阐述了:内存硬件通信的基本单位是字节(8bit),而不同数量字节的组合会形成不同的数据类型,那么单从整型数据类型上映射事物,还是有不足之处:int类型虽然可以存储年龄属性,如果再想存储其他数据属性,就不够用了,人类的中还包括性别、身高、体重等属性,那么就需要更多的数据类型来表示其属性值。
而这些属性之间的关系是密不可分的,都属于人类这个事物的一部分,少了任何一个属性就无法完整表示人类这个事物在现实世界中的真实表现。因此在 C 语言中引出了结构体的概念,程序员可以使用struct关键词来自定义数据类型,它允许在结构体中存储不同类型的数据项。
通俗点讲,就是将 C 语言本身定义的一些数据类型(整数类型,字符串类型)进行组合,形成一段更有现实意义的内存格子,程序员再以这个结构体定义的内存单元格进行数据操作会更符合事物现实规律。
举例:
定义一个学生,有性别和年龄属性:性别可以使用 female 和 male 的单词首字母表示,所用 char 数据类型,年龄使用 int 数据类型,那么使用定义 Student 结构体之后,在程序中就会将 Student 类型的内存以 5 个字节(1 个字节+ 4 个字节)来表示这种数据类型:
1.4 typedef
C 语言提供了 typedef 关键字,程序员可以使用它来为数据类型取一个别名。
1 | typedef struct Sutdent { |
上述代码中,定义了struct Sutdent数据类型的别名为:STUDENT,在定义语句之后的任意地方都可以使用这个别名来代表struct Sutdent这种数据类型。
1.5 指针
指针是 C 语言的灵魂,指针就是地址。
第 1 小节描述了内存是一块连续的内存空间,是由一个个 bit 组成,8 个 bit 组成一个字节,它是计算机操作数据的基本单位,因此对于程序来说,一块内存有很多内存单元(8 bit 为一个字节的单元格)。
此时不禁疑惑:计算机如何聪明地知道第一个单元格和其后面的三个单元格联接在一起,是表示int数据类型?它又是怎么知道第一个单元格和后面所有单元都没有联系,它就是孤立的char类型?还有它有时候是怎么知道第一个单元格和后面四个连续在一起是表示Student数据类型呢?
好比,有些租户租了一套房子,这是一家人,还有写租户租了四套连续的房子,这四套连在一起是属于一家。我们可以人为定义 1 个字节用于表示char数据类型,4 个字节表示int数据类型,是如何在连续的单元格中,准确无误地知道哪些单元格连在一起就是某种数据类型,哪些单元格和另一些不与之连续的单元格是一个整体,用来表示某种特殊数据呢?
由于内存的连续存储空间特性,可以将内存单元格进行人为编号, 这个编号的术语就是内存地址,CPU 能够操作内存中的数据就是通过地址总线进行对内存的精准操作,因此计算机只需要记住地址,就能知道其地址上对应的数据是什么。
因此,当定义一个int类型的数据,就是告知CPU,在读取内存的时候,记得在某某编号的位置开始读取内存,读取 4 个字节单元,读出来的数据就是有意义的数据。由此可以得知,数据类型的定义就是用来约束CPU从某个地址逐个字节读取数据,读到第几个字节表示一个有实际意义的函数。
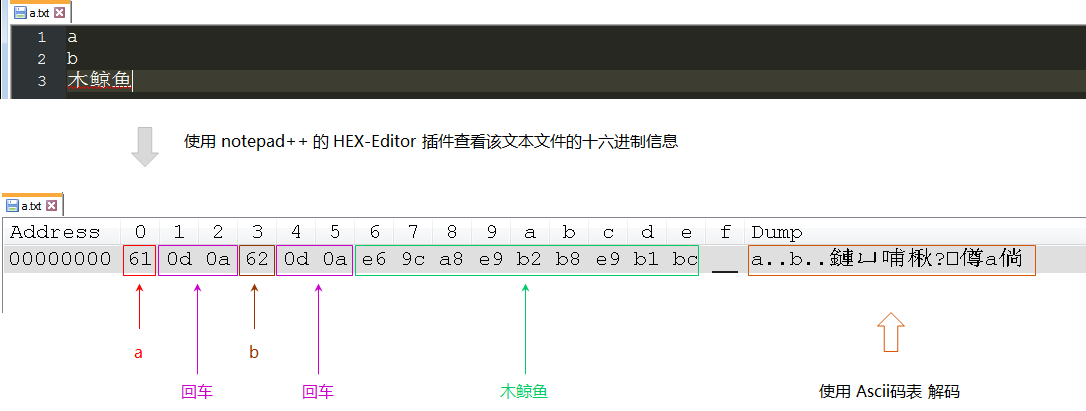
下图表示的是,使用文件编辑器使用UTF-8字符集编码的文本文件,查看该十六进制信息,可以看到字母 a 和 b 占了 1 个字节,回车占了 2 个字节,在 UTF-8 字符集规范中,一个汉字占用 3 个字节,因此”木鲸鱼”这一串字符串占了 9 个字节。
那么,在 C 语言中是如何告诉 CPU 地址和当前地址要读取几个字节数据表示一个有意义的数据呢?
答案就是指针变量类型,当定义一个 int 数据类型的数据,使用一个字母 a 来表示它,以便在程序的其他地方可以复用,那么就定义成以下语句:
1 | int a = 10; |
当程序执行这句话的时候,就是告知计算机在内存中分配一块 4 个字节的内存单元用来保存 10 这个数值,那么当计算机分配成功,一定是通过地址总线进行内存分配的,因此只要内存分配成功就表示有个唯一的地址空间,从这个地址开始之后的 4 个字节内存空间是表示数字 10 的。
在 C 语言中,会使用某种特定的语法来获取分配成功的变量的地址,即在定义的变量名前面加个&符号,就能得到内存分配成功之后的地址:
1 | &a // 使用 &变量名 的语法方式获取地址 |
因此,为何 C 语言为何引入地址(指针)的概念的目的就出来了,是用来记录数据存在内存的哪个位置,并在后续的时候让 CPU 知道去内存的哪里找数据。
此时有个新的问题,光知道地址,是无法知道数据是什么,因为从已知地址之后的任意字节空间都可以组合成数据,因此指针的概念引入还不够,还需要知道当前地址(指针)之后需要读取多少字节表示一个完整有意义的数据,而这个问题就是指针类型概念引入的目的,指针类型就是在告知计算机,当前地址之后的多少个字节是连续操作读取的,在 C 语言中,使用语法:
1 | 数据类型 * |
因此,定义了上述的&a取出地址之后,需要使用int *的指针类型来修饰。
此时又引出一个问题,当定义了一个地址,怎么知道地址对应的数据是多少,这个在 C 语言中得到很好的处理,只需要在指针变量前面加*符号即可读取到当前地址对应的数据内容了:
1 |
|
也是说,*指针变量的方式是将会读取指针变量所在的地址,并从它的指针类型推导出应该从这个地址的内存单元开始读取几个内存单元。
注意:指针有别于指针变量,指针是地址,而指针变量是地址(指针)对应的变量的变量。开发者常说的指针是指指针变量,这是种约定俗成的口头表述概念,不是学术上的地址概念。
1.6 动态内存分配
C 语言中提供了标准的内存管理函数库,库中的函数可以在<stdlib.h>头文件中找到,用来帮助程序员在堆中创建内存:
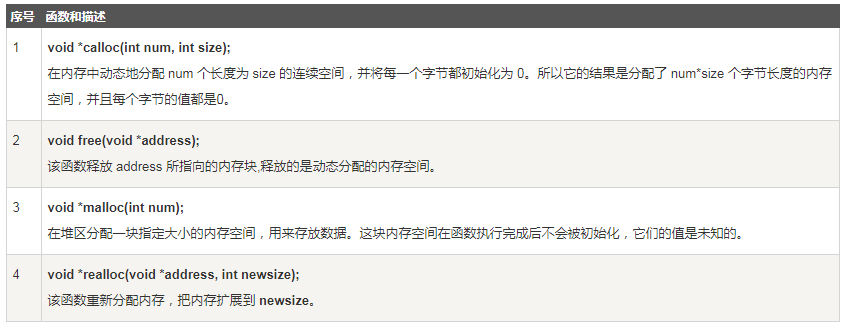
注意:void *类型表示未确定类型的指针。C、C++ 规定void *类型可以通过类型转换强制转换为任何其它类型的指针。
说明:堆中的内存是完全由程序员自己来管理何时回收,因此程序员需要时刻小心自己在堆中申请的内存释放的时机,不需要再使用的内存没有及时回收,会产生内存泄漏风险,这是一件很恐怖的事情。
想要申请一块内存,用来存储 int 数据类型的数据,使用如下命令:
1 | int * pTemp; |
想要申请一块内存,用来存储Student数据类型的数据时,使用如下命令:
1 | struct Student * PStudent; |
注意到在申请内存的时候,在malloc()函数中,填写的数值是使用sizeof()函数动态计算要存储数据的数据类型大小,这样使得 C 程序的可移植性更好,因为在不同的系统中,相同的数据类型,可能其所占的内存空间是不一样的。
二、链表之 C 语言描述
链表
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer)。
单向链表
链表中最简单的一种是单向链表,它包含两个域,一个信息域和一个指针域。这个链接指向列表中的下一个节点,而最后一个节点则指向一个空值。

一个单向链表包含两个值: 当前节点的值和一个指向下一个节点的链接
一个单向链表的节点被分成两个部分。第一个部分保存或者显示关于节点的信息,第二个部分存储下一个节点的地址。单向链表只可向一个方向遍历。
链表的应用
链表用来构建许多其它数据结构,如堆栈,队列和他们的派生。
1.2 设计思路
链表是由节点进行链接的,那么链表中最小的单元就是节点,因此以链表的节点为一个结构体,其结构体中存放着数据和下一个节点的地址:
1 | struct Node { |
设计好链表的数据节点之后,就需要考虑,节点和节点之间虽然都是使用上一个节点的属性关联着自己的地址,自己关联着下一个节点的地址,那么链表中,谁才是头,谁才是尾:
- 头节点,其数据类型和其他子节点一样
- 头节点不含有数据data,下一个节点的地址可以指向NULL,也可以指向有效的节点(含有数据的节点)的地址
- 尾节点,其数据类型和其他子节点一样
- 尾节点其数据节点中含有数据,但其下一个节点的地址永远是指向NULL
1.3 代码实现
1 |
|
参考资料:郝斌 数据结构自学视频