
一、信息就是位 + 上下文
作者使用的标题是:信息就是位 + 上下文,那么问题来了:什么是位?什么是上下文?
计算机系统是由硬件和系统软件组成的,它们共同工作来运行应用程序。所有计算机系统都有相似的硬件和软件组件,它们执行着相似的功能。
从某种意义上来说,本书的目的就是要帮助你了解当你在系统上执行 hello 程序时,系统发生了什么以及为什么会这样。
1 | // hello 程序 |
hello 程序的生命周期是从一个源程序(或者说源文件)开始的,即程序员利用编辑器创建并保存的文本文件,文件名是 hello.c。源程序实际上就是一个由值 0 和 1 组成的位(bit)序列,8 个位被组织成一组,称为字节。每个字节表示程序中某个文本字符。
hello 源程序是文本编辑器编写的一个文件,使用 HxD (免费的十六进制和磁盘数据编辑器)对源文件进行源码查看:
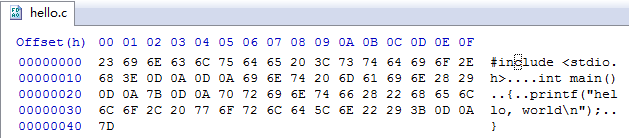
从上图可以看见,所有的源码字符最终都会被转为对应的数字。像 hello.c 这样只由 ASCII 字符构成的文件称为文本文件,所有其他文件都称为二进制文件。hello.c 的表示方法说明了一个基本的思想 :系统中所有的信息(包括磁盘文件、存储器中的程序、存储器中存放的用户数据以及网络上传送的数据),都是由一串位表示的。区分不同数据对象的唯一方法是我们读到这些数据对象时的上下文。比如,在不同的上下文中,一个同样
的字节序列可能表示一个整数、浮点数、字符串或者机器指令。
构成计算机信息存储单元是 bit(位),如果以 1 位为单位记录信息,未免有点低效。如果采用 8 个位为一个字节单位,可以组合出 256 种不同的符号表示,这样传输也方便,也便于计算机存储信息。
知道位的概念还不够,计算机对当前的某一个位中的信息可以通过字符编码规则得知,但是文本文件除外,还有纯二进制的文件(图片、音视频),计算机如何得知某几个位连接起来是一串有意义的数据,并知道从哪里截取开始到哪里结束,这就需要通过上下文来得知。
二、ASCII 码
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
计算机里,一个字节有 8 个 bit(位),用二进制(1 和 0)组合表示,则有 2 的 8 次方种可能数字,从零开始计数,则为 0 - 255,早期的计算机科学家们以为这 256 种数字够表示日常使用的符号信息了(英文字母,阿拉伯数字,控制字符等)。
第一部分:ASCII 非打印控制字符表
ASCII 表上的数字 0–31 分配给了控制字符,用于控制像打印机等一些外围设备。例如,12 代表换页/新页功能。此命令指示打印机跳到下一页的开头。
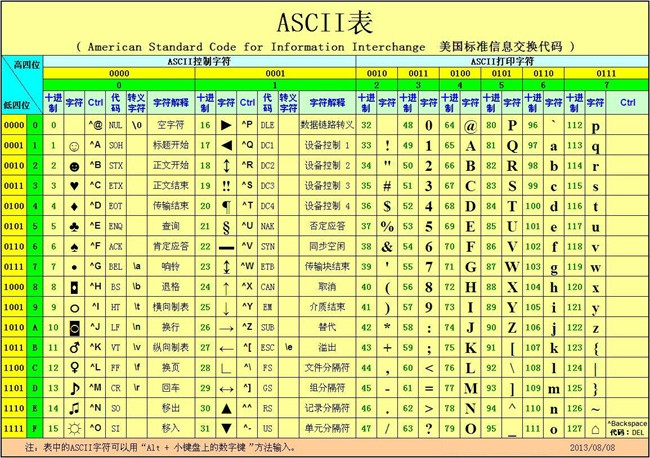
第二部分:ASCII 打印字符
数字 32–126 分配给了能在键盘上找到的字符,当您查看或打印文档时就会出现。数字 127 代表 DELETE 命令。
第三部分:扩展 ASCII 打印字符
扩展的 ASCII 字符满足了对更多字符的需求。扩展的 ASCII 包含 ASCII 中已有的 128 个字符(数字 0–32 显示在下图中),又增加了 128 个字符,总共是 256 个。
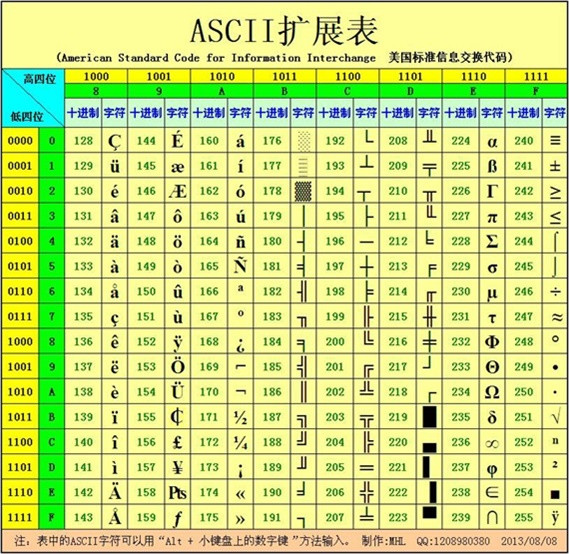
ASCII 码表有它的局限性:随着全世界人都在使用计算机,而全世界使用符号的种类远超过了 256 种,因此 ASCII 码表已经装不下更多的符号信息(非英语国家的文字符号信息:拉丁文、中文、日韩文等),于是计算机科学家们又规定出了 Unicode(中文译为:万国码、国际码、统一码、单一码),即全球通用字符集的标准。
Unicode 标准规定:使用两个字节单位表示一个数字,因此可以表示符号的种类为 2 的16 次方,也就是 65536 种,这样全世界人使用的符号信息都可以囊括。
值得注意的是 Unicode 是一种计算机工业标准,而不是指定是什么字符集实现,它涵兼容了 ASCII 码表规则,因此目前所有的计算都会至少认识 ASCII 码表规则。
现在国际常用的UTF-8 编码就是遵循了 Unicode 标准的一种字符集实现。
三、程序被其他程序翻译成不同的格式
hello.c 是肉眼可直接识别的文本文件,但作为机器来说,它只认识二进制数字(物理逻辑上对应的是:不同大小电流或高低的电压),文件均附生在操作系统之上,我们需要一套完整的流程将源文件翻译成机器可以直接看懂并执行的可执行文件,执行这四个阶段的程序(预处理器、编译器、汇编器和链接器)一起构成了编译系统(compilation system)。

使用 gcc++ 编译工具编译 hello.c 源文件:
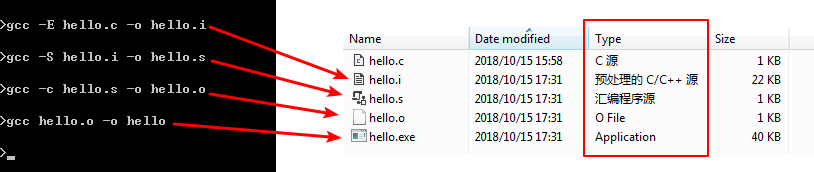
gcc 常用编译命令
无选项编译链接
用法:gcc hello.c
作用:将 hello.c 预处理、汇编、编译并链接形成可执行文件。这里未指定输出文件,默认输出为a.out。选项 -o
用法:gcc hello.c -o hello
作用:将 hello.c 预处理、汇编、编译并链接形成可执行文件 hello。-o 选项用来指定输出文件的文件名。选项 -E
用法:gcc -E hello.c -o hello.i
作用:将 hello.c 预处理输出 hello.i 文件。选项 -S
用法:gcc -S hello.i
作用:将预处理输出文件 hello.i 汇编成 hello.s 文件。选项 -c
用法:gcc -c hello.s
作用:将汇编输出文件 hello.s 编译输出 hello.o 文件。无选项链接
用法:gcc hello.o -o hello
作用:将编译输出文件test.o链接成最终可执行文件test。选项 -O
用法:gcc -O1 hello.c -o hello
作用:使用编译优化级别1编译程序。级别为1~3,级别越大优化效果越好,但编译时间越长。
- 预处理阶段。预处理器(cpp)根据以字符 # 开头的命令,修改原始的 C 程序。比如 hello.c 中第 1 行的 #include 命令告诉预处理器读取系统头文件 stdio.h 的内容,并把它直接插入到程序文本中。结果就得到了另一个 C 程序,通常是以 .i 作为文件扩展名。
- 编译阶段。编译器(cc1)将文本文件 hello.i 翻译成文本文件 hello.s,它包含一个汇编语言程序。汇编语言程序中的每条语句都以一种标准的文本格式确切地描述了一条低级机器语言指令。汇编语言是非常有用的,因为它为不同高级语言的不同编译器提供了通用的输出语言。例如,C 编译器和 Fortran 编译器产生的输出文件用的都是一样的汇编语言。
- 汇编阶段。接下来,汇编器(as)将 hello.s 翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序(relocatable object program)的格式,并将结果保存在目标文件 hello.o 中。hello.o 文件是一个二进制文件,它的字节编码是机器语言指令而不是字符。如果我们在文本编辑器中打开 hello.o 文件,看到的将是一堆乱码。
- 链接阶段。请注意,hello 程序调用了 printf 函数,它是每个 C 编译器都会提供的标准 C 库中的一个函数。printf 函数存在于一个名为 printf.o 的单独的预编译好了的目标文件中,而这个文件必须以某种方式合并到我们的 hello.o 程序中。链接器(ld)就负责处理这种合并。结果就得到 hello 文件,它是一个可执行目标文件(或者简称为可执行文件),可以被加载到内存中,由系统执行。