
Lambda
简介
Lambda 是一个 匿名函数,我们可以把 Lambda 表达式理解为是 一段可以传递的代码(将代码像数据一样进行传递)。使用它可以写出更简洁、更灵活的代码。作为一种更紧凑的代码风格,使Java的语言表达能力得到了提升。
从匿名类到 Lambda 的转换示例1
在多线程开发中需要手动 new 一个匿名的实现了 Runnable 接口的类,并执行 start() 方法启动一个新的线程,
注意:下面代码只是方法调用,并不是启动新的线程。仅用 Runnable 接口示例如果使用 Lambda 表达式该如何编写代码。
示例一:
1 |
|
使用 Lambda 表达式会让代码显得更简洁,其程序运行的效果还是一样的:
1 |
|
从匿名类到 Lambda 的转换示例2
1 |
|
Lambda 表达式简化:
1 |
|
语法
Lambda 表达式:在Java 8 语言中引入的一种新的语法元素和操作符。这个操作符为-> , 该操作符被称为 Lambda 操作符或 箭 头操作符。它将 Lambda 分为两个部分:
左侧:指定了 Lambda 表达式需要的 参 数 列表
右侧:指定了 Lambda 体,是抽象方法的实现逻辑,也即 Lambda 表达式要执行的功能。
语法格式一
无参,无返回值
1 | Runnable r2 = () -> {System.out.println("woodwhales.github.io");}; |
语法格式二
Lambda 需要一个参数,但是没有返回值。
1 | Runnable runnable = () -> { |
语法格式三
数据类型可以省略 ,因为可由编译器推断得出,称为类型推断
1 | Consumer<String> consumer1 = (String str) -> { |
语法格式四
Lambda 若只需要一个参数时,参数的小括号可以省略
1 | Consumer<String> consumer3 = str -> { |
语法格式五
Lambda 需要两个或以上的参数,多条执行语句,并且可以有返回值
1 | Comparator<Integer> comparator1 = (x, y) -> { |
语法格式六
当 Lambda 体只有一条语句时,return 与大括号若有,都可以省略
1 | Comparator<Integer> comparator2 = (x, y) -> Integer.compare(x, y); |
类型推断
上述 Lambda 表达式中的参数类型都是由编译器推断得出的。Lambda 表达式中无需指定类型,程序依然可以编译,这是因为 javac 根据程序的上下文,在后台推断出了参数的类型。Lambda 表达式的类型依赖于上下文环境,是由编译器推断出来的。这就是所谓的类型推断。

函数式接口(Functional)
概念
如果一个接口中只声明了一个抽象方法,则此接口就称为函数式接口。
Lambda 表达式可以创建该接口的对象。
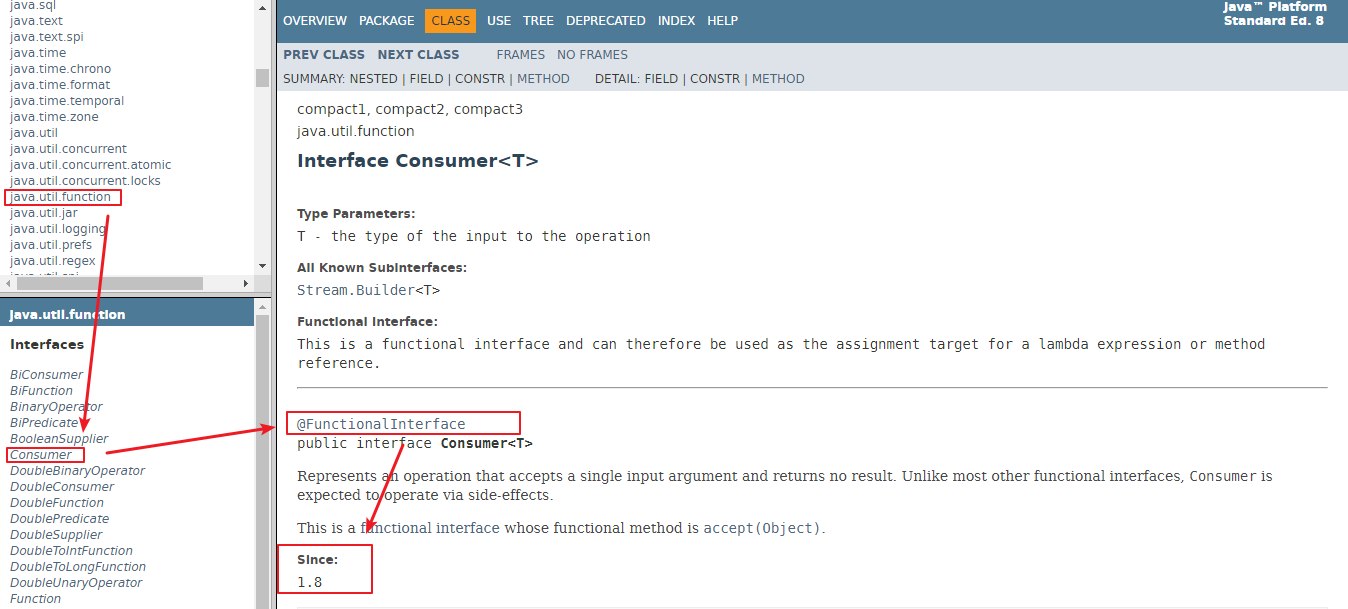
我们可以在一个接口上使用@FunctionalInterface注解,这样做可以检查它是否是一个函数式接口。同时 javadoc 也会包含一条声明,说明这个接口是一个函数式接口。
在 JDK 1.8 API 文档上会显示带有
@FunctionalInterface注解:
自定义函数式接口
我们可以在一个接口上使用@FunctionalInterface 注解,自己创建一个接口,并仅仅提供一个方法,使用@FunctionalInterface注解:
1 | /** |
注意:使用了函数式接口注解这个接口,这个接口有超过一个抽象方法,会报编译异常。
使用 Lambda 表达式创建上述自定义的接口:
1 | public static void say(MyFunctionalInterface myFunctionalInterface) { |
在java.util.function包下定义了Java 8 的丰富的函数式接口:
| 序号 | 接口名及描述 |
|---|---|
| 1 | BiConsumer代表了一个接受两个输入参数的操作,并且不返回任何结果。 |
| 2 | BiFunction代表了一个接受两个输入参数的方法,并且返回一个结果。 |
| 3 | BinaryOperator代表了一个作用于于两个同类型操作符的操作,并且返回了操作符同类型的结果。 |
| 4 | BiPredicate代表了一个两个参数的boolean值方法。 |
| 5 | BooleanSupplier代表了boolean值结果的提供方。 |
| 6 | Consumer代表了接受一个输入参数并且无返回的操作。 |
| 7 | DoubleBinaryOperator代表了作用于两个double值操作符的操作,并且返回了一个double值的结果。 |
| 8 | DoubleConsumer代表一个接受double值参数的操作,并且不返回结果。 |
| 9 | DoubleFunction代表接受一个double值参数的方法,并且返回结果。 |
| 10 | DoublePredicate代表一个拥有double值参数的boolean值方法。 |
| 11 | DoubleSupplier代表一个double值结构的提供方。 |
| 12 | DoubleToIntFunction接受一个double类型输入,返回一个int类型结果。 |
| 13 | DoubleToLongFunction接受一个double类型输入,返回一个long类型结果。 |
| 14 | DoubleUnaryOperator接受一个参数同为类型double,返回值类型也为double 。 |
| 15 | Function接受一个输入参数,返回一个结果。 |
| 16 | IntBinaryOperator接受两个参数同为类型int,返回值类型也为int 。 |
| 17 | IntConsumer接受一个int类型的输入参数,无返回值 。 |
| 18 | IntFunction接受一个int类型输入参数,返回一个结果 。 |
| 19 | IntPredicate:接受一个int输入参数,返回一个布尔值的结果。 |
| 20 | IntSupplier无参数,返回一个int类型结果。 |
| 21 | IntToDoubleFunction接受一个int类型输入,返回一个double类型结果 。 |
| 22 | IntToLongFunction接受一个int类型输入,返回一个long类型结果。 |
| 23 | IntUnaryOperator接受一个参数同为类型int,返回值类型也为int 。 |
| 24 | LongBinaryOperator接受两个参数同为类型long,返回值类型也为long。 |
| 25 | LongConsumer接受一个long类型的输入参数,无返回值。 |
| 26 | LongFunction接受一个long类型输入参数,返回一个结果。 |
| 27 | LongPredicateR接受一个long输入参数,返回一个布尔值类型结果。 |
| 28 | LongSupplier无参数,返回一个结果long类型的值。 |
| 29 | LongToDoubleFunction接受一个long类型输入,返回一个double类型结果。 |
| 30 | LongToIntFunction接受一个long类型输入,返回一个int类型结果。 |
| 31 | LongUnaryOperator接受一个参数同为类型long,返回值类型也为long。 |
| 32 | ObjDoubleConsumer接受一个object类型和一个double类型的输入参数,无返回值。 |
| 33 | ObjIntConsumer接受一个object类型和一个int类型的输入参数,无返回值。 |
| 34 | ObjLongConsumer接受一个object类型和一个long类型的输入参数,无返回值。 |
| 35 | Predicate接受一个输入参数,返回一个布尔值结果。 |
| 36 | Supplier无参数,返回一个结果。 |
| 37 | ToDoubleBiFunction接受两个输入参数,返回一个double类型结果。 |
| 38 | ToDoubleFunction接受一个输入参数,返回一个double类型结果。 |
| 39 | ToIntBiFunction接受两个输入参数,返回一个int类型结果。 |
| 40 | ToIntFunction接受一个输入参数,返回一个int类型结果。 |
| 41 | ToLongBiFunction接受两个输入参数,返回一个long类型结果。 |
| 42 | ToLongFunction接受一个输入参数,返回一个long类型结果。 |
| 43 | UnaryOperator接受一个参数为类型T,返回值类型也为T。 |
对于 JDK1.8 中提供的这么多函数式接口,开发中常用的函数式接口有以下几个 Predicate,Consumer,Function,Supplier:
内置四大核心函数式接口
| 函数式接口 | 参数类型 | 返回类型 | 用途 |
|---|---|---|---|
| Consumer |
T | void | 对类型为T的对象应用操作,包含方法:void accept(T t) |
| Supplier |
无 | T | 返回类型为T的对象,包含方法:T get() |
| Function<T, R> 函数型接口 | T | R | 对类型为T的对象应用操作,并返回结果。结果是R类型的对象。包含方法:R apply(T t) |
| Predicate |
T | boolean | 确定类型为T的对象是否满足某约束,并返回 boolean 值。包含方法:boolean test(T t) |
消费型接口
Consumer
void accept(T t)
java.util.function.Consumer
1 | public void showPrice(double money, Consumer<Double> consumer){ |
供给型接口
Supplier
T get()
java.util.function.Supplier
1 | public static Properties readFile(String fileName) { |
函数型接口
Function<T,R> R apply(T t)
java.util.function.Function<T, R>接口定义了一个叫作apply的方法,它接受一个泛型T的对象,并返回一个泛型R的对象。如果需要定义一个Lambda,将输入的信息映射到输出,可以使用这个接口(比如提取苹果的重量,或把字符串映射为它的长度),通常称为功能型接口。
1 | // 实现用户密码 Base64加密操作 |
断定型接口
Predicate
boolean test(T t)
1 | public List<String> filterString(List<String> list, Predicate<String> predicate){ |
其他函数式接口
| 函数式接口 | 参数类型 | 返回类型 | 用途 |
|---|---|---|---|
| BiFunction<T, U, R> | T, U | R | 对类型为 T, U 参数应用操作,返回 R 类型的结果。 包含方法为: R apply(T t, U u) |
| UnaryOperator |
T | T | 对类型为T的对象进行一元运算,并返回T类型的结果。 包含方法为: T apply(T t) |
| BinaryOperator |
T, T | T | 对类型为T的对象进行二元运算,并返回T类型的结果。 包含方法为: T apply(T t1, T t2) |
| BiConsumer<T, U> | T, U | void | 对类型为T, U 参数应用操作。 包含方法为: void accept(T t, U u) |
| BiPredicate<T,U> | T, U | boolean | 包含方法为: boolean test(T t, U u) |
| ToIntFunction ToLongFunction ToDoubleFunction |
T | int long double |
分别计算int、long、double值的函数 |
| IntFunction LongFunction DoubleFunction |
int long double |
R | 参数分别为int、long、double 类型的函数 |
方法引用
当要传递给 Lambda 体的操作,已经有实现的方法了,可以使用方法引用。方法引用,本质上就是 Lambda 表达式,而 Lambda 表达式作为函数式接口的实例。所以方法引用,也是函数式接口的实例。
方法引用可以看做是 Lambda 表达式深层次的表达。换句话说,方法引用就是 Lambda 表达式,也就是函数式接口的一个实例,通过方法的名字来指向一个方法,可以认为是 Lambda 表达式的一个语法糖。
使用格式: 类(或对象)::方法名
具体分为如下的三种情况:
情况1:对象 :: 实例方法
情况2:类 :: 静态方法
情况3:类 :: 非静态方法
情况1 和情况3 的方法引用使用的要求:要求接口中的抽象方法的形参列表和返回值类型与方法引用的方法的形参列表和返回值类型相同。
情况1、对象 :: 非静态方法
1 | // Consumer 中的 void accept(T t) |
情况2、类 :: 静态方法
1 | // Comparator 中的 int compare(T t1,T t2) |
情况3、类 :: 实例方法
1 | // Comparator 中的 int comapre(T t1,T t2) |
构造器引用
构造器引用与函数式接口相结合,自动与函数式接口中方法兼容。格式为:ClassName::new
可以把构造器引用赋值给定义的方法,要求构造器参数列表要与接口中抽象方法的参数列表一致,且方法的返回值即为构造器对应类的对象。
1 | // Supplier 中的 T get() |
数组引用
数组引用和构造器引用类似,格式为:type[]::new
1 | // Function 中的 R apply(T t) |
Stream API
官方文档: https://docs.oracle.com/javase/8/docs/api/java/util/stream/Stream.html
Java8中有两大最为重要的改变。第一个是 Lambda 表达式;另外一个则是 Stream API。
Stream API ( java.util.stream) 把真正的函数式编程风格引入到 Java 中。这是目前为止对 Java 类库最好的补充,因为 Stream API 可以极大提供 Java 程序员的生产力,让程序员写出高效率、干净、简洁的代码。
Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。 使用 Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询。也可以使用 Stream API 来并行执行操作。简言之,Stream API 提供了一种高效且易于使用的处理数据的方式。
实际开发中,项目中多数数据源都来自于 Mysql,Oracle 等。但现在数据源可以更多了,有 MongDB,Redis 等,而这些 NoSQL 的数据就需要 Java 层面去处理。
Stream 和 Collection 集合的区别:Collection 是一种静态的内存数据结构,而 Stream 是有关计算的。前者是主要面向内存,存储在内存中,后者主要是面向 CPU,通过 CPU 实现计算。
Stream 到底是什么
Stream 是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。
- Stream 自己不会存储元素。
- Stream 不会改变源对象。相反,他们会返回一个持有结果的新 Stream。
- Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。
Stream 的操作三个步骤
Stream API 可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。
步骤1:创建 Stream
一个数据源(如:集合、数组),获取一个流
步骤2:中间操作
一个中间操作链,对数据源的数据进行处理
步骤3:终止操作(终端操作)
一旦执行终止操作,就执行中间操作链,并产生结果。终止操作结束之后,当前被终止的流中数据不会再被使用。
1 | +--------------------+ +------+ +------+ +---+ +-------+ |
中间操作总是会惰式执行,调用中间操作只会生成一个标记了该操作的新 stream。
结束操作会触发实际计算,计算发生时会把所有中间操作积攒的操作以 pipeline 的方式执行,这样可以减少迭代次数。计算完成之后 stream 就会失效。
虽然大部分情况下 stream 是容器调用Collection.stream()方法得到的,但 stream 和 collections 有以下不同:
无存储。stream 不是一种数据结构,它只是某种数据源的一个视图,数据源可以是一个数组,Java 容器或 I/O channel等。
为函数式编程而生。对 stream 的任何修改都不会修改背后的数据源,比如对 stream 执行过滤操作并不会删除被过滤的元素,而是会产生一个不包含被过滤元素的新 stream。
惰式执行。stream 上的操作并不会立即执行,只有等到用户真正需要结果的时候才会执行。
可消费性。stream 只能被“消费”一次,一旦遍历过就会失效,就像容器的迭代器那样,想要再次遍历必须重新生成。
流的使用及分类
和以前的Collection操作不同, Stream操作还有两个基础的特征:
- Pipelining:中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路(short-circuiting)。
- 内部迭代:以前对集合遍历都是通过 Iterator 或者 For-Each 的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream 提供了内部迭代的方式, 通过访问者模式(Visitor)实现。
流的使用

流操作的分类

流操作分类为:
中间操作(Intermediate)
无状态操作:filter / map / peek 等,指元素的处理不受之前元素的影响。
有状态操作:distinct / sorted / limit 等,指该操作只有拿到所有元素之后才能继续下去。
终端操作(Terminal)
非短路操作:forEach / collect / count 等,指遇到某些符合条件的元素就可以得到最终结果。
短路操作:anyMatch / findFirst / findAny 等,指必须处理所有元素才能得到最终结果。
Stream 的创建
方式1:通过集合
Java8 中的 Collection 接口被扩展,提供了两个获取流的方法:
顺序流:default Stream
并行流:default Stream
1 | Test |
方式2:通过数组
Java8 中的 Arrays 的静态方法 stream() 可以获取数组流:
static
1 |
|
方式3:通过Stream 的of()
可以调用Stream类静态方法 of(), 通过显示值创建一个流。它可以接收任意数量的参数:
public static
1 |
|
方式4:创建无限流
可以使用静态方法 Stream.iterate() 和 Stream.generate(),创建无限流:
迭代:public static
生成:public static
1 |
|
Stream 的中间操作
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理!而在终止操作时一次性全部处理,称为惰性求值(中间操作只是对操作进行了记录,只有结束操作才会触发实际的计算)。
类型1:筛选与切片
| 方法 | 描述 |
|---|---|
| filter(Predicate p) | 过滤,接收 Lambda ,并从流中排除某些元素 |
| distinct() | 筛选,通过流所生成元素的 hashCode() 和 equals() 去除重复元素 |
| limit(long maxSize) | 截断流,使其元素不超过给定数量 |
| skip(long n) | 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补 |
代码示例:
1 |
|
类型2:映射
| 方法 | 描述 |
|---|---|
| map(Function f) | 接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。 |
| mapToDouble(ToDoubleFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 DoubleStream。 |
| mapToInt(ToIntFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 IntStream。 |
| mapToLong(ToLongFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 LongStream。 |
| flatMap(Function f) | 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流 |
代码示例:
1 |
|
类型3:排序
| 方法 | 描述 |
|---|---|
| sorted() | 产生一个新流,其中按自然顺序排序 |
| sorted(Comparator com) | 产生一个新流,其中按比较器顺序排序 |
代码示例:
1 |
|
Stream 的终止操作
终端操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如:List、Integer,甚至是 void 。
注意:流进行了终止操作后,不能再次使用。
类型1:匹配与查找
| 方法 | 描述 |
|---|---|
| allMatch(Predicate p) | 检查是否匹配所有元素 |
| anyMatch(Predicate p) | 检查是否至少匹配一个元素 |
| noneMatch(Predicate p) | 检查是否没有匹配所有元素 |
| findFirst() | 返回第一个元素 |
| findAny() | 返回当前流中的任意元素 |
| count() | 返回流中元素总数 |
| max(Comparator c) | 返回流中最大值 |
| min(Comparator c) | 返回流中最小值 |
| forEach(Consumer c) | 内部迭代(使用 Collection 接口需要用户去做迭代,称为外部迭代。相反,stream API 使用内部迭代——它帮你把迭代做了) |
代码示例:
1 |
|
类型2:规约
| 方法 | 描述 |
|---|---|
| reduce(T iden, BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回 T |
| reduce(BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回 Optional |
备注:map 和 reduce 的连接通常称为 map-reduce 模式,因 Google 用它来进行网络搜索而出名。
代码示例:
1 |
|
类型3:收集
| 方法 | 描述 |
|---|---|
| collect(Collector c) | 将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法 |
Collector 接口中方法的实现决定了如何对流执行收集的操作(如收集到 List、Set、Map)。
代码示例:
1 |
|
Collectors
另外, Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例,具体方法与实例如下表:
官方文档:https://docs.oracle.com/javase/8/docs/api/java/util/stream/Collectors.html
| 工厂方法 | 返回类型 | 用途 | 示例 |
|---|---|---|---|
toList |
List |
把流中所有项目收集到一个 List | List projects = projectStream.collect(toList()); |
toSet |
Set |
把流中所有项目收集到一个 Set,删除重复项 | Set projects = projectStream.collect(toSet()); |
toCollection |
Collection |
把流中所有项目收集到给定的供应源创建的集合 | Collection projects = projectStream.collect(toCollection(), ArrayList::new); |
counting |
Long |
计算流中元素的个数 | long howManyProjects = projectStream.collect(counting()); |
summingInt |
Integer |
对流中项目的一个整数属性求和 | int totalStars = projectStream.collect(summingInt(Project::getStars)); |
averagingInt |
Double |
计算流中项目 Integer 属性的平均值 | double avgStars = projectStream.collect(averagingInt(Project::getStars)); |
summarizingInt |
IntSummaryStatistics |
收集关于流中项目 Integer 属性的统计值,例如最大、最小、 总和与平均值 | IntSummaryStatistics projectStatistics = projectStream.collect(summarizingInt(Project::getStars)); |
joining |
String |
连接对流中每个项目调用 toString 方法所生成的字符串 | String shortProject = projectStream.map(Project::getName).collect(joining(", ")); |
maxBy |
Optional |
按照给定比较器选出的最大元素的 Optional, 或如果流为空则为 Optional.empty() | Optional fattest = projectStream.collect(maxBy(comparingInt(Project::getStars))); |
minBy |
Optional |
按照给定比较器选出的最小元素的 Optional, 或如果流为空则为 Optional.empty() | Optional fattest = projectStream.collect(minBy(comparingInt(Project::getStars))); |
reducing |
归约操作产生的类型 | 从一个作为累加器的初始值开始,利用 BinaryOperator 与流中的元素逐个结合,从而将流归约为单个值 | int totalStars = projectStream.collect(reducing(0, Project::getStars, Integer::sum)); |
collectingAndThen |
转换函数返回的类型 | 包含另一个收集器,对其结果应用转换函数 | int howManyProjects = projectStream.collect(collectingAndThen(toList(), List::size)); |
groupingBy |
Map> |
根据项目的一个属性的值对流中的项目作问组,并将属性值作 为结果 Map 的键 | Map> projectByLanguage = projectStream.collect(groupingBy(Project::getLanguage)); |
partitioningBy |
Map> |
根据对流中每个项目应用断言的结果来对项目进行分区 | Map> vegetarianDishes = projectStream.collect(partitioningBy(Project::isVegetarian)); |
Project 类:
1 | import lombok.Builder; |
Optional
官方文档:https://docs.oracle.com/javase/8/docs/api/java/util/Optional.html
到目前为止,臭名昭著的空指针异常是导致 Java 应用程序失败的最常见原因。以前,为了解决空指针异常,Google 公司著名的 Guava 项目引入了 Optional 类,Guava 通过使用检查空值的方式来防止代码污染,它鼓励程序员写更干净的代码。受到 Google Guava 的启发,Optional 类已经成为 Java 8 类库的一部分。
Optional
Optional类的 Javadoc 描述如下:这是一个可以为 null 的容器对象。如果值存在则isPresent()方法会返回 true,调用get()方法会返回该对象。
创建Optional 类对象的方法
Optional.of(T t) : 创建一个 Optional 实例,t必须非空
Optional.empty() : 创建一个空的 Optional 实例
Optional.ofNullable(T t) :t可以为null
代码示例:
1 |
|
判断Optional 容器中是否包含对象
boolean isPresent() : 判断是否包含对象
void ifPresent(Consumer<? super T> consumer) :如果有值,就执行 Consumer 接口的实现代码,并且该值会作为参数传给它。
代码示例:
1 |
|
获取 Optional 容器的对象
T get(): 如果调用对象包含值,返回该值,否则抛异常
T orElse(T other) :如果有值则将其返回,否则返回指定的other对象
T orElseGet(Supplier<? extends T> other) :如果有值则将其返回,否则返回由 Supplier 接口实现提供的对象。
T orElseThrow(Supplier<? extends X> exceptionSupplier) :如果有值则将其返回,否则抛出由Supplier接口实现提供的异常。
代码示例:
1 |
|
从执行输出的结果可以看出:当 Optional.ofNullable() 接收到的对象:
元素是 null,返回 orElse()中的结果是符合 API 描述的。
元素即不为 null,orElse() 也会被执行一次,并且仅仅是执行一下,并不会返回该方法中的结果。这看起来有点浪费资源,多此一举。
因此可以使用 orElseGet():
1 |
|
Optional.get()方法获取 Optional 容器中的值,执行下面代码会发现,容器中的值是 null,get() 的时候会抛出空指针异常:
1 |
|
Optional.ifPresent()方法会在容器中的元素为 null 的时候执行这个方法中的程序:
1 |
|
从上述结果可以看出,当容器中的元素不为空的时候,执行ifPresent()方法中的程序,并且这个方法不返回任何值,仅仅是”消费掉”元素。
时间日期API
第三次引入的 API 是成功的,并且Java 8中引入的 java.time API 已经纠正了过去的缺陷,将来很长一段时间内它都会为我们服务。
Java 8 吸收了 Joda-Time 的精华,以一个新的开始为 Java 创建优秀的 API。新的 java.time 中包含了所有关于本地日期(LocalDate)、本地时间(LocalTime)、本地日期时间(LocalDateTime)、时区(ZonedDateTime)
和持续时间(Duration)的类。历史悠久的 Date 类新增了 toInstant() 方法,用于把 Date 转换成新的表示形式。这些新增的本地化时间日期 API 大大简化了日期时间和本地化的管理。
LocalDate/LocalTime/LocalDateTime
LocalDate、LocalTime、LocalDateTime 类是其中较重要的几个类,它们的实例是不可变的对象,分别表示使用 ISO-8601 日历系统的日期、时间、日期和时间。它们提供了简单的本地日期或时间,并不包含当前的时间信息,也不包含与时区相关的信息。
- LocalDate 代表 IOS 格式(yyyy-MM-dd)的日期,可以存储 生日、纪念日等日期。 只对年月日做出处理。
- LocalTime 表示一个时间,而不是日期。 只对时分秒纳秒做出处理。
- LocalDateTime 是用来表示日期和时间的,这是一个最常用的类之一。 同时可以处理年月日和时分秒。
三种共同特点:
- 相比于 Date 和 Calendar,他们是线程安全的;
- 它们是不可变的日期时间对象;
注:ISO-8601日历系统是国际标准化组织制定的现代公民的日期和时间的表示法,也就是公历。
代码示例:
1 |
|
LocalDateTime 常用 API
| 方法 | 描述 |
|---|---|
| now() now(Zoneld zone) |
静态方法,根据当前时间创建对象 ; 指定时区的对象 |
| of() | 静态方法,根据指定日期,时间创建对象 |
| getDayOfMonth() | 获得月份天数(1-31) |
| getDayOfYear() | 获取年份天数(1-366) |
| getDayOfWeek() | 获得星期几 |
| getYear() | 获得年份 |
| getMonth() getMonthValue() |
获得月份(返回枚举值如:January) ; 返回数字(1-12) |
| getHour() getMinute() getSecond() |
获得当前对象的时,分,秒 |
| withDayOfMonth() withDayOfYear() withMonth() withYear() |
将月份天数;年份天数;月份;年份修改为指定的值并且返回新的对象,因为LocalDate等是不变性的 |
| plusDays() plusWeeks() plusMonths() plusYears() plusHours() |
向当前对象添加几天、几周、几个月、几年,几小时 |
| minusDays() minusWeeks() minusMonths() minusYears() minusHours() |
从当前对象减去几月、几周、几个月、几年、几小时 |
| isLeapYear() | 判断是否为闰年 |
| isBefore isEqual isAfter |
检查日期是否在指定日期前面,相等,后面 |
上述 API 在 LocalDate 、LocalTime 和 LocalDateTime 三者几乎是通用的。
瞬时(Instant)
Instant:时间线上的一个瞬时点。 这可能被用来记录应用程序中的事件时间戳。
在处理时间和日期的时候,我们通常会想到年,月,日,时,分,秒。然而,这只是时间的一个模型,是面向人类的。第二种通用模型是面向机器的,或者说是连续的。在此模型中,时间线中的一个点表示为一个很大的数,这有利于计算机处理。在UNIX中,这个数从1970年开始,以秒为的单位;同样的,在Java中,也是从1970年开始,但以毫秒为单位。
java.time包通过值类型Instant提供机器视图,不提供处理人类意义上的时间单位。Instant表示时间线上的一点,而不需要任何上下文信息,例如,时区。概念上讲,它只是简单的表示自1970年1月1日0时0分0秒(UTC)开始的秒数。因为java.time包是基于纳秒计算的,所以Instant的精度可以达到纳秒级。
(1 ns = 10 -9 s) 1秒 = 1000毫秒 =10^6微秒=10^9纳秒
常用 API:
| 方法 | 描述 |
|---|---|
| now() | 静态方法,返回默认的UTC时区的Instant类的对象 |
| atOffset(ZoneOffset offset) | 将此瞬间与偏移组合起来创建一个OffsetDateTime |
| toEpochMilli() | 返回1970-01-01 00:00:00到当前的毫秒数,即时间戳 |
| ofEpochMilli(long epochMilli) | 静态方法,返回在1970-01-01 00:00:00基础加上指定毫秒数之后的Instant类的对象 |
| ofEpochSecond(long epochSecond) | 静态方法,返回在1970-01-01 00:00:00基础加上指定秒数之后的Instant类的对象 |
时间戳是指格林威治时间 1970 年 01 月 01 日 00 时 00 分 00 秒( 北京时间 1970 年 01 月 01日 08 时 00 分00 秒) 起至现在的总秒数。
代码示例:
1 |
|
根据当前系统的时区值,获取当前时间:
1 |
|
时期格式化(DateTimeFormatter)
java.time.format.DateTimeFormatter 类:该类提供了三种格式化方法:
预定义的标准格式。如:ISO_LOCAL_DATE_TIME;ISO_LOCAL_DATE;ISO_LOCAL_TIME
本地化相关的格式。如:ofLocalizedDateTime(FormatStyle.LONG)
自定义的格式。如:ofPattern(“yyyy-MM-dd HH:mm:ss”)
常用API
| 方法 | 描述 |
|---|---|
| ofPattern(String pattern) | 静态方法 , 返 回一 个指定字符串格式的 DateTimeFormatter |
| format(TemporalAccessor t) | 格式化一个日期、时间,返回字符串 |
| parse(CharSequence text) | 将指定格式的字符序列解析为一个日期、时间 |
最常用的方式使用ofPattern(String pattern)创建自定义的格式化工具。
时间转时间字符串,代码示例:
1 |
|
时间字符串转时间,代码示例:
1 |
|
新日期与传统日期的转换
| 类 | To 遗留类 | From 遗留类 |
|---|---|---|
| java.time.Instant 与 java.util.Date | Date.from(instant) | date.toInstant() |
| java.time.Instant与java.sql.Timestamp | Timestamp.from(instant) | timestamp.toInstant() |
| java.time.Zoned DateTime与java.util.GregorianCalendar | GregorianCalendar.from(zonedDateTime) | cal.toZonedDateTime() |
| java.time.LocalDate与java.sql.Time | Date.valueOf(localDate) | date.toLocalDate() |
| java.time.LocalTime与java.sql.Time | Date.valueOf(localDate) | date.toLocalTime() |
| java.time.LocalDateTime与java.sql.Timestamp | Timestamp.valueOf(localDateTime) | timestamp.toLocalDateTime() |
| java.time.ZoneId与java.util.TimeZone | Timezone.getTimeZone(id) | timeZone.toZoneId() |
| java.time.format.DateTimeFormatter 与 java.text.DateFormat | formatter.toFormat() | 无 |
JDBC 与 新API 结合
如果想要在 JDBC 中,使用 Java8 的日期 LocalDate、LocalDateTime,则必须要求数据库驱动的版本不能低于 4.2
最新JDBC映射将把数据库的日期类型和Java 8的新类型关联起来:
| SQL | Java |
|---|---|
| date | LocalDate |
| time | LocalTime |
| timestamp | LocalDateTime |