
一、前言
1. 文件编码格式通用设置
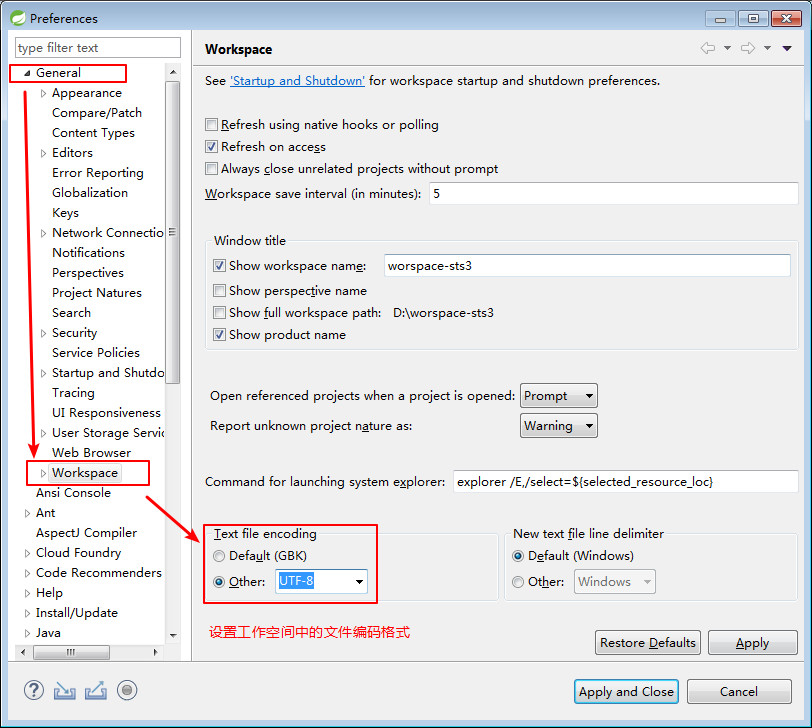
在使用 eclipse 开发工具的时候,首先需要确定工作空间的编码格式:
windows菜单 –» perferences选项 –» General选项中的Workspace工作空间选项,设置文件编码格式。
2. 文件编码格式单独设置
单个项目编码格式设置:项目 –» 右键 –» Properties –» Text file encoding
单个页面文件编码格式设置:页面 –» 右键 –» Properties –» Text file encoding
一、response 响应乱码
response 响应数据回浏览器之前,程序可以将数据转换成字节流的形式输出内容,也可以使用字符流的形式输出内容,但是字符流形式仅限于文本数据,因此前者在 web 开发中需要更谨慎的关注和理解原理。
1.2 字节流响应
在 web 工程中创建一个简单的servlet
1 | public class ResponseDemo1 extends HttpServlet { |
注意,此时的源码文件编码类型为:UTF-8,查看文件编码类型可右击文件属性,在Resource选项中的Text file encoding中可见。
servlet 资源访问路径映射配置:
1 | <servlet> |
使用 IE 浏览器访问 web 工程,此时浏览器显示中文乱码,并且通过查看网页编码可知,默认使用GB2312编码解析响应文本。
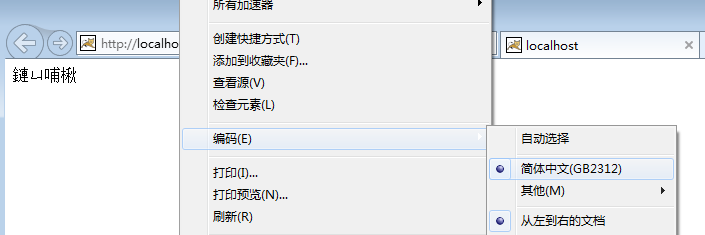
为什么默认使用GB2312码表呢?因为 windows 系统本地的时区语言是中文,因此浏览器会默认使用GB2312解码响应体。当手动更改编码格式为UTF-8时,浏览器显示汉字内容正常。
那么问题来了,默认用户都是电脑小白,不能等用户看到网页乱码再自己手动修改浏览器解码格式,这似乎不是雅的 web 程序可以出现的问题。
解决方案 1:响应头设置
于是在程序响应回浏览器之前,设置响应头:
1 | String data ="木鲸鱼"; |
通过响应头的设置,使得浏览器必须以程序设置的编码格式解析 html 文本内容:
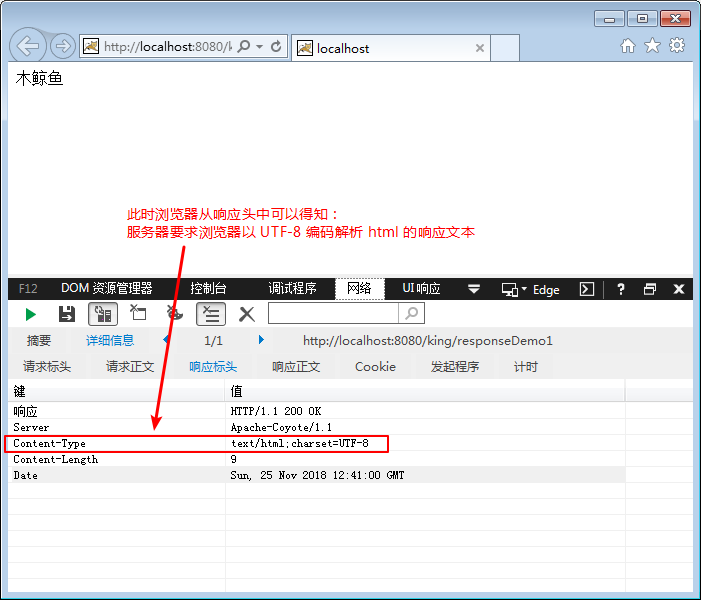
注意:在上述代码中,存在一个很隐蔽的隐患,因为源码文件就是UTF-8字符集编码的代码,并且工作空间设置的是UTF-8编码,因此在问题 1中设置浏览器为UTF-8编码解析文本的时候才能正常显示,因此对于输出字节流的时候,也就是在上述源码中对data字符串对象进行数组转换的时候指定字符集。
1 | String data ="木鲸鱼"; |
解决方案 2:模拟 http 头文件
在 html 文件中,可以使用meta标签中的http-equiv属性指定:
1 | String httpHeader = "<html><meta http-equiv='Content-Type' content='charset=UTF-8'><body>"; |
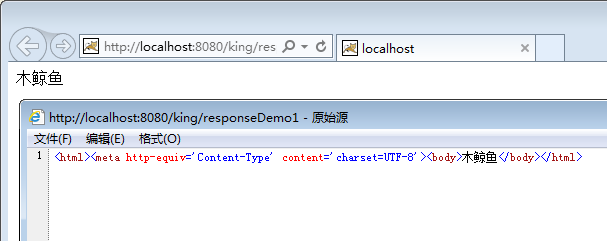
查看源码可知,html 解析了meta标签及其属性。另外需要注意:在 W3C 文档中说明了使用 http-equiv 已经不是规定 HTML 文档的字符集的唯一方式:
HTML 4.01 与 HTML5之间的差异:
HTML 4.01:<meta http-equiv="content-type" content="text/html; charset=UTF-8">
HTML5:<meta charset="UTF-8">
参考地址:http://www.w3school.com.cn/tags/tag_meta.asp
1.2 字符流响应
由于大多数数据都是以字符文本的形式响应回浏览器,那么可以将数据转成字符流传输。
1 | String data ="木鲸鱼"; |
注意,即使是使用字符流传输,在网络传输过程中,均将字符数据按照一定的码表解析成机器码进行数字传输,到了目的地再通过指定的码表进行翻译解析。因此,上面简单的使用字符流数据响应回浏览器的时候一定是按照某种编码格式进行解析成二进制信息并传输的,因为项目使用的是 Tomcat 服务器,所以默认的编码格式为ISO8859-1,在 Tomcat 官方文档中的过滤器一章有这样一句说明,意思就是说,如果不指定字符集就使用 ISO8859-1传输数据:
The HTTP specification is clear that if no character set is specified for media sub-types of the “text” media type, the ISO-8859-1 character set must be used.
参考地址:http://tomcat.apache.org/tomcat-7.0-doc/config/filter.html
解决方案:设置 response 字符集编码及响应头
设置 response 响应对象以特定字符集编码格式读取数据,并设置响应头,要求浏览器以特定格式解析,即可保证数据不会乱码:
1 | String data ="木鲸鱼"; |
注意:Java 设计者在设计HttpServletResponse对象的时候提供了setContentType()方法,它的作用就是通知浏览器以指定字符集解析文本数据,并要求 response 对象以指定字符集读取数据。
扩展:
响应头的信息中不允许包含中文编码,只能是 ASCII 码字符,那么对于图片文件需要传输文件名,就必须使用URLEncoding类对字符串进行转码:
1 | response.setHeader("Content-Disposition", "attachment;filename=" + URLEncoder.encode(data,"UTF-8")); |
二、request 请求乱码
目前,request 请求的主流请求类型为GET和POST,其中GET请求的方式,可以是在表单中提交,也可以在浏览器地址栏中显示请求。
2.1 表单中的 POST 请求
post 请求数据在发送时一定经过某种字符集编码成二进制信息,再经过网络传输到服务器,post 请求在 html 页面和 jsp 页面中会有不同的表现。
[1] post 请求在html页面表现:
在 html 页面中,如果有meta信息指定字符集编码,则使用此编码传输数据,没有则使用操作系统默认编码,中文操作系统一般使用GB2312字符集编码。
下面 html 页面指定了meta信息:
1 | <meta http-equiv="Content-Type" content="text/html; charset=GBK"> |
此时数据传输到服务器是经过UTF-8编码解析,后台获取请求数据
1 | String username = request.getParameter("username"); |
此时一定是会出现中文乱码问题,因为在request.getParameter()的瞬间,Tomcat 会将网络数据中的二进制查询ISO8859-1字符集试图解码成可见字符并返回。
「 解决方案 」
在request.getParameter()调用之前,要求 request 对象获取请求参数的时候指定字符集:
1 | request.setCharacterEncoding("UTF-8"); |
也就是 request 对象获取请求参数时,不要依赖服务器的 API 实现,而是使用程序员自己的字符集编码。
完美解决方案代码:
1 | request.setCharacterEncoding("UTF-8"); |
[2] post 请求在 jsp 页面表现:
在 jsp 页面中,可以在@page中指定"contentType",也可以在 html 文本中指定meta信息,当有@page指定charset时,此配置信息优与meta配置,就是说下面 jsp 页面在浏览器中显示的默认编码格式为GBK:
1 | <%@ page language="java" contentType="text/html; charset=GBK" pageEncoding="UTF-8"%> |
对于服务器获取参数的解决方案和在上一小结点是一致的。
2.2 表单中及地址栏中的 GET 请求
页面及地址栏中的GET请求,在数据传输时使用的编码,不依赖于页面的meta或者contentType信息,GET 请求的本质是使用统一资源标志符,当表单中的GET请求发生之后,其请求地址会打印到地址栏中。
注意:在 IE 浏览器中不可以使用中文作为参数直接发请求,而 chrome 浏览器会将中文进行URL编码再发请求,至于其他浏览器是否自动转码,笔者没测试了。
GET请求由 Tomcat 服务容器接收,会将这个URL中的参数对进行ISO8859-1编码,官方文档作出了下面的解释:
在 Tomcat 系统参数配置中提到了关于
URIEncoding的解释:
This specifies the character encoding used to decode the URI bytes, after %xx decoding the URL. If not specified, ISO-8859-1 will be used.
参考地址:https://tomcat.apache.org/tomcat-7.0-doc/config/http.html
解决方案 1
从上述描述中可知,在 Tomcat 服务器的conf配置文件目录下的server.xml中配置了连接器信息:
1 | <Connector connectionTimeout="20000" port="8080" protocol="HTTP/1.1" redirectPort="8443"/> |
在Connector连接器中增加URIEncoding="UTF-8"属性配置。
解决方案 2
在 Tomcat 的server.xml下的connector属性中添加参数useBodyEncodingForURI="true"(注意,并不是对整个 URI 都采用 BodyEncoding,只是应用于 Query String 而已)。这样,Tomcat 便会用request.setCharacterEncoding()指定的编码来解析 GET 参数了。
解决方案 3
在 servlet 中手动转码,在 Tomcat 服务器中,将ISO8859-1转码成UTF-8:
1 | String username = request.getParameter("username"); |
解决方案 4
实现过滤器,对所有的请求进行拦截过滤,并在web.xml中配置filter和filter-mapping:
1 | public class EncodingFilter implements Filter { |
推荐使用方案 4。
三、jsp 页面的编码原理
3.1 jsp 页面的编码三阶段
JSP要经过两次的”编码”,第一阶段会用pageEncoding,第二阶段会用UTF-8至UTF-8,第三阶段就是由 Tomcat 出来的网页, 用的是contentType。
第一阶段:JVM 将.jsp文件编译为.java文件。JVM 先读取pageEncoding的值,根据该值去读取.jsp文件,然后由指定的编码方案生成UTF-8的.java文件。
证明:在 Tomcat 服务器目录下
work文件夹下的Catalina目录中找到.java文件(由jsp源码文件生成),其文件的编码是UTF-8格式,文件中的文本内容是根据pageEncoding的字符集进行记录。
第二阶段:JVM 将java文件转换为class文件,从UTF-8至UTF-8。这个过程就与任何编码的设置都没有关系了,经过这个阶段后.java文件就转换成了统一的UTF-8编码的class文件了。
第三阶段:服务器将处理的结果返回给浏览器,这个阶段则依靠contentType的charset,如果设置了charset则浏览器就会使用指定的编码格式进行解码,否则采用默认的ISO-8859-1编码格式进行解码处理。
证明:在
jsp对应的.java文件源码中可以看到 response 响应已经指定了Content-Type:
response.setContentType(“text/html; charset=UTF-8”);
3.2 jsp 页面中设置字符集
1. pageEncoding
1 | <%@ page pageEncoding="UTF-8"%> |
上文中第一阶段,使用该值去读取jsp文件,为避免中文乱码,跟jsp文件编码一致;对服务器响应进行重新编码,即jsp的输出流在浏览器中显示的编码(不是主要作用)。
2. contentType
1 | <%@ page contentType="text/html;charset=UTF-8"%> |
使用该值对服务器响应进行重新编码,即jsp的输出流在浏览器中显示的编码;对表单get和post请求数据编码;上文中第一阶段,使用该值去读取jsp文件(不是主要作用)。
3. META
1 | <META http-equiv="Content-Type" content="text/html;charset=UTF-8"> |
网页的编码信息 ,说明页面制作所使用的编码。
因此编写jsp页面的最佳实践是统一配置成UTF-8编码:
1 | <%@ page contentType=”text/html;charset=UTF-8” pageEncoding="UTF-8"%> |